大模型浪潮的席卷速度,超越了历史上任何一场技术革命。
年初,OpenAI发布Sora,马斯克、周鸿祎不惜溢美之词,狂热蔓延全世界。正当大家还在惊叹“未来已来”,Anthropic公司宣布Claude-3正式发布,并宣布在AI逻辑基准测试中超过了ChatGPT-4。与此同时,Google和马斯克同时跳入开源大战,分别推出Gemma和Grok。
全球大模型的竞争热潮,从小众圈层向外扩散,像涟漪一样,播散向全世界。一场大模型的无限竞争就此打响。全球科技巨头携带着大笔充沛的资金、漂亮履历的技术人才将战场烧的更加火热。
但冷静一看,目前世界上公认的大模型领军者,大多却是年轻的AI企业:估值高达290亿美元的OpenAI,成立于2015年;被称为OpenAI“最强竞争对手”的大模型公司Anthropic成立于2021年;“欧洲新秀”Mistra创立至今,刚到一年。三家闪耀的AI明星公司的员工加起来却可能不到一千人,只是科技大厂的一个部门的人数。
为什么这场对大模型王冠的追逐战,不在巨头的射程范围内?
01 为什么荣光属于AI企业?
首先,打破一个认知误区:大模型并不是一场单单依靠资源的军备竞赛。
在ChatGPT横空出世后,一个广为流传的说法是,OpenAI成功的关键在于背靠微软Azure云上的数万张A100卡,成本高达数亿美元。更有甚者认为大模型的胜率取决于资源的充沛程度。
然而,今年3月,美国初创公司 Databricks 突然公布旗下开源大语言模型 DBRX,号称是全球最强开源大模型,参数规模达到 1320 亿,表现更是超越 Meta 的 Llama2、Mistral AI 的 Mixtral,以及马斯克旗下 xAI 公司刚刚开源的 Grok-1。
更重要的是,他们只花了 2 个月和 1000 万美元,在性能全面超越 GPT-3.5 的同时,训练时间和成本都只有 GPT-3.5 的一小部分。
事实上,资源对于任何领域的竞争都很重要,但资源在大模型领域却不是万能的、更不是唯一因素。而AI企业相比科技巨头,有一个得天独厚的优势,就在于技术探索上的灵活性。
Google曾是人工智能深度学习领域里当之无愧的王者。2016年,击败人类围棋冠军李世石的阿尔法go就是出自谷歌Deepmind,而在自然语言模型领域,谷歌也曾遥遥领先。
然而,2022年ChatGPT横空出世。实际上拉开身位差距的是技术路线上的分歧。谷歌追逐的自然语言模型应该是一系列的垂类,参数相对较小、适用场景面相对较窄的模型,而OpenAI认为应该做一个通用的海量参数,海量数据训练的超级大模型。
OpenAI当年的梦想看来是天方夜谭。但即便在与谷歌的较量中长期落于下风,OpenAI也没有放弃将GPT作为唯一路线。阿尔特曼的一句话给出了答案——“创业公司做什么都很难,那不如抓住大机会。”(Startups are very hard no matter what you do , you may as well go after a big opportunity.)
相比于AI企业的灵活性,科技巨头在押注技术路线上却很难如此孤注一掷,这也一定程度上造成了动作的迟缓。这也注定了,AI的最新方向大概率要靠AI企业去探索。
海外AI明星公司鳞次栉比、星光璀璨。那么问题来了,中国领域的AI明星公司在哪?
02 “ 中国大模型五虎”浮出水面
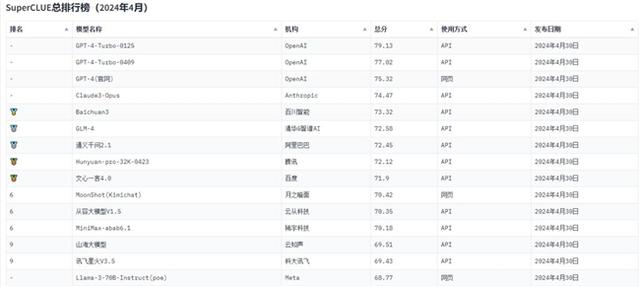
一张SuperCLUE评测榜单揭开了中国大模型五虎的秘密。

刨除BAT,榜单上展现着中国最强AI企业的身影,分别是百川智能、智谱AI、月之暗面、MiniMax、云从科技。

百川智能成立于 2023 年 4 月,创始人为前搜狗公司 CEO 王小川。成立后短短数月,百川智能便跻身科技独角兽行列,成立至今更是连续发布了11款基础大模型。

智谱AI成立于2019年,今年初已完成新一轮融资。创始人张鹏,毕业于清华大学计算机科学与技术系。几年来,公司连续发布了GLM系列大模型、ChatGLM、CodeGeeX代码大模型等,已成为国内最早也是最有大模型研发经验的企业之一。
MiniMax成立于2021年,背后的掌舵者闫俊杰毕业于中科院自动化所,在商汤科技担任副总裁期间,负责搭建深度学习的工具链和底层算法,以及通用智能的技术发展。联合创始人杨斌,则是闫俊杰在中科院的校友。
同样来势汹汹的还有月之暗面(Moonshot AI)——2023年,月之暗面接连完成两轮共计近20亿人民币的融资,估值超25亿美金。月之暗面成立于2023年3月由三位清华校友创办,带头人则是90后学霸杨植麟。
至此,加上云从科技,中国AI大模型五虎呼之欲出。
云从科技曾是“AI四小龙”中A股第一股,也是国内AI三驾马车中,唯一一家具备全内资背景的企业。在业内,云从科技与商汤科技、旷视科技、依图科技并称“AI四小龙”,但论起光环与热度,最年轻的云从科技,却是最“顶流”的存在。
“AI国家队选手”、“中国科学院孵化企业”、“中国AI第一梯队企业”、“首个同时承担国家发展和改革委人工智能基础平台、应用平台,科技部开放平台等重大项目建设任务、并参与国家及行业标准制定的人工智能企业”等称号,让云从科技自2015年诞生以来,始终处于行业聚光灯下。
如今,云从科技又在大模型时代昂首阔步。
03 被时代眷顾的优等生
去年五月,位列国内人工智能第一梯队的云从科技,正式发布了AI智能体(AI-agent)领域的战略级产品——“从容多模态大模型”。
云从科技研究院产品总监孙进在接受媒体采访时表示:从容大模型在内部已经历了多轮迭代。1.5版本时,平衡上下文长度、模型性能与推理成本是迭代重点。从容大模型 2.0 版本已经完成,3.0版本重点是多模态能力--跳过文本直接处理不同模态的数据。
不只是对话体验,从容大模型还可以编程、写作、解题等。云从还对“从容”与ChatGPT进行横向对比演示,在对同一真题的解答过程中,从容大模型的答题速度相较更快,但推理能力、语义理解能力已超过GPT 3.5,略低于GPT4.0。

经第三方机构SuperClue、C-Eval等综合评测,从容大模型综合性能位列全球前五。同时,从容大模型具备多模态能力,在视觉、跨模态领域10次刷新世界纪录。
据云从科技介绍,公司已布局了数十个行业大模型,并研发了DataGPT、智能客服、AI鼠标等多个泛AI智能应用,成为云从科技布局AI智能体(AI-agent)的重要抓手。
同时,云从科技与华为昇腾联合提出应对智算基础设施挑战的解决之道,开启“国产化算力+智算”的新布局。目前,双方已合作推出大模型应用底座——从容大模型训推一体机,并与天津港集团、首链科技、今世缘、国网山东、中国电信等合作伙伴一起,成功帮助港口、医药、制造、电力、银行等行业客户落地生成式AI应用场景。
云从科技连续踏中两波AI浪潮,离不开其深厚的科研背景。
云从科技的创始人周曦,曾以中科院“百人计划”专家身份引进回国,担任中国科学院重庆绿色智能技术研究院信息所副所长等职位。用了半年时间,他在全国范围内组建起一支拥有20多位专业人才的团队,并入选中国科学院A类战略性先导科技专项,成为其中唯一的人脸识别团队。
在日后,这只团队成为了计算机视觉领域的国家队,其技术成果先后被用在多个省份,在alpha go尚未大战李世石让AI一夜爆火之前,就悄然将这一技术带到了普通人的生活之中。
一直到2015年4月,33岁的周曦,却放弃别人艳羡的“铁饭碗”,选择内部创业,牵头成立云从科技,专攻人脸识别领域。
“很惊讶,因为在这个领域很少见到愿意放弃现有职位全力投入创业的科学家。”海通证券某人士在接受媒体采访时表示,“海通作为云从的第一个项目,在应用实现上有特别多困难,周曦当时把整个研发弄到上海来攻坚了一周,系统上线后到现在再也没出过问题。”
从2015年开始,人脸识别作为计算机视觉领域最易落地的赛道,开始逐渐形成风口。在筚路蓝缕七年之后,云从交上了他的答卷:作为唯一一家全内资AI企业,顺利登陆科创板,被称为“AI国家队”。
翻开云从科技的招股书,我们可以看到,云从科技的创始团队大多来自中科院、中科大。公司拥有近600名科研人员,研发人员占比超过50%,核心团队曾先后10次获得国内外人工智能领域桂冠。

如今全球大模型竞争风起云涌,新的科技浪潮席卷各行各业,中国人工智能领域在焦虑和追赶中又一次走到了十字路口。
如何书写这一次新的篇章,既是云从科技新的课题,同样也是所有中国AI企业迫切的使命。
