字数统计:2919字 预计阅读时间:约6分钟

日前Openai公布了视频生成AI“sora”的概述和技术报告。获得全世界的关注与惊叹,我们一起解读一下技术报告,来探讨对行业的影响。
01One
视频生成模型
视频生成模型是构建物理世界通用模拟器的一条有前途的途径。与之前的研究(RNN、GAN、Transformer、Diffusion 模型)不同,sora 是视觉数据的通用模型,可以生成长达1分钟的高分辨率视频。它还可以生成各种长度、长宽比和分辨率的视频和图像。
02Two
将视频数据转化为简单图像
就像大型语言模型(LLM)使用文本标记(即文字或字符)来处理和理解文本信息一样,Sora通过使用视觉元素,即图像块来理解和处理视觉数据。过去的研究已经证明,这种将视觉信息划分成小块的方法是一种有效的处理方式。
通过将视频数据压缩到一个较小的、包含更少数据的空间里,我们可以将视频转换成一系列的小图像块。这意味着视频不再以传统的连续帧方式存在,而是被转化为一组可以表示视频内容的图像块。

03Three
视频压缩网络
训练一个网络,该网络接收原始视频作为输入并获取时间和空间压缩的潜在表示。Sora 在这个压缩的潜在空间上进行训练,然后在这个压缩的潜在空间中生成视频。并且还通过将生成的潜在空间重新映射到像素空间来训练解码器模型。04Four
用于视频生成的时空潜在补丁/缩放变压器
Sora 是一种扩散转换器,可通过接收噪声补丁和文本提示等条件信息来生成视频。随着扩散变压器的学习,质量得到了提高(下面的视频)。
05Five
可变的持续时间、分辨率、宽高比
在以前的方法中,图像和视频是通过将其压缩到诸如 256 x 2564之类的分辨率来进行训练的,但 sora 使用相同的分辨率进行学习。因此,可以生成宽屏(1920 1080px)、垂直视频(1080 1920)以及介于两者之间的所有视频。
06Six
改进的框架和构图
以原始长宽比学习视频可以改善构图和取景。
下面左侧的视频是使用裁剪为正方形的视频进行训练的,右侧的视频是使用原始宽高比进行训练的。

不过,即使是256*256的模型,镜面反射也很自然了……
07Seven
语言理解
训练模型生成描述性字幕:我们首先训练一个高级模型,使其能够为视频内容生成高度描述性的字幕。这意味着模型可以自动理解视频中发生的事件,并以文字的形式详细描述这些内容。
为所有视频自动生成字幕:
一旦模型训练完成,我们就使用它来处理训练数据集中的所有视频,为它们自动生成描述性字幕。这样,每个视频都会有一段精确的文字描述,帮助观众更好地理解视频内容。
使用GPT转换用户提示为详细指令:
在进行推理时,即模型根据新的输入做出反应时,用户可以提供简短的提示。我们的系统会内部使用GPT这样的先进技术,将这些简短的提示转化为更加详细、解释性的长提示。这样做可以使模型更准确地理解用户的意图,并据此生成更为相关和精确的字幕。
通过这种方法,我们的技术不仅能够提升视频的可访问性和理解度,还能根据用户的具体需求定制内容,提供更加丰富、个性化的观看体验。


08Eight
通过图像和视频进行提示
如下图提示:在一座华丽的历史大厅里,巨大的海浪达到顶峰并开始冲击。两名冲浪者抓住时机,熟练地驾驭海浪。

sora可以向前或向后延长视频时间。
可以扩展它以创建无限循环的视频。
也可以进行视频到视频的转换。
您还可以无缝连接两个视频。
09Nine
新兴的模拟功能
Sora可以模拟现实世界中的人、动物和环境的某些方面。这些属性的出现并没有对 3D、物体等产生明确的偏差。这些纯粹是通过扩展而出现的。
3D 一致性。Sora 可以生成带有动态摄像机运动的视频。当摄像机移动或旋转时,人和场景元素在 3D 空间中一致移动。

保持视频一致性。还支持遮挡。

通过考虑随时间的变化,可以绘制一幅图画的延续。
还可以模拟数字世界。
10Ten
考虑对AI领域未来研发的影响
1.对图像/视频字幕领域的影响
Sora 在一个数据集上进行训练,该数据集使用大量视频的专有视频字幕模型进行注释。考虑到它能够生成具有如此一致性的高质量视频,它被认为是一个相当高质量的视频捕获模型。(技术报告中包含一些生成的示例。)。此外,由于它可以生成Minecraft模拟环境,因此虚拟空间的视频字幕也被认为是相当出色的。
首先,作为sora一部分的视觉编码器模型是一个比CLIP更好的编码器模型,而且它似乎可以用于各种下游任务,例如“对象检测”和“行为预测”。
2.对游戏和视频制作领域的影响
关于使用 NeRF 使用 sora 生成的图像进行 3D 重建的帖子已成为热门话题。
从这个例子中可以看出,sora 生成的图像似乎有可能以 3D 形式恢复。技术报告中也提到了这一点,并表明sora有能力创建如此一致的镜头。近年来, 3D高斯喷射技术因其能够实现高质量、低成本的3D重建而成为热门研究领域。随着sora和3d-GS的发展,从文本即时生成3D场景的未来指日可待。 另一方面,可编辑性也是一个问题。 不过,考虑到 sora可以以图像为条件生成视频,并且可以通过文字提示编辑视频 ,编辑3D场景可能会变得更容易,因为sora本身的可编辑性很高,但我可以想象事实并非如此。图像本身已经可以轻松地从文本进行编辑。

而且,空似乎对于作曲也有着深厚的造诣。

预计通过用文本提示指导构图,可以生成具有所需剪辑的视频。
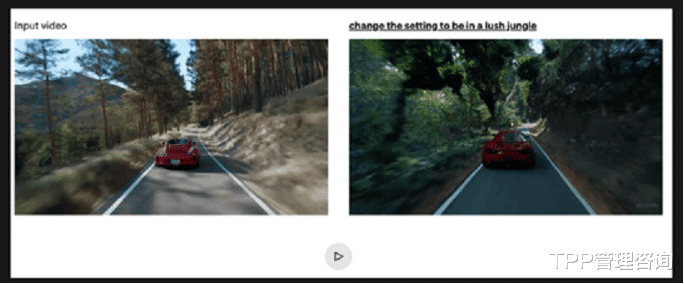
这对于电影制作的预可视化制作似乎很有用。然而,除非你尝试一下,否则你不会知道它的准确性或有用性。
看看sora的模型结构,你大概可以给出多个图像作为图像条件。通过输入多个角色图像和地点图像作为条件,似乎可以生成类似戏剧的场景。
11Eleven
总结
在sora的技术报告中,表示sora模拟物理世界的能力是通过缩放来实现的。缩放法则和突现能力一直是LLM的热门话题,但sora中的突现能力影响更大……随着LLM的出现,各种与语言打交道的业务,sora 的出现将为处理视频的业务带来重大变化。话虽如此,相信更多的人还是愿意享受科技的变化,充分利用新技术。
