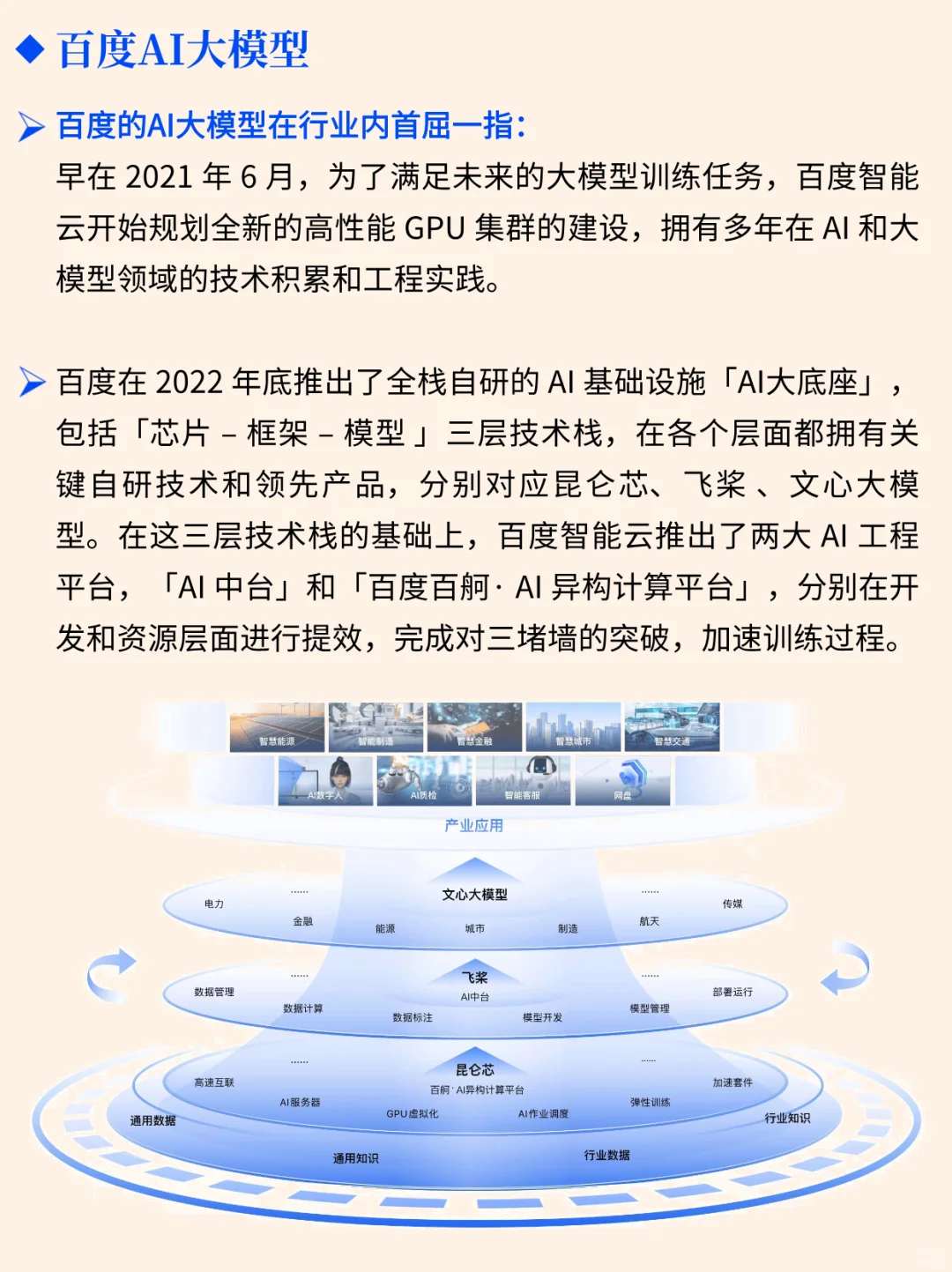
[向右R] 这两天看到一则消息,说李彦宏在和内部员工交流时,聊到了大模型的三个常见的误解,让我深受启发,特来总结一下和大家分享:
[一R]观点1:不同模型之间的差距不是越来越小,而是会越来越大;
[二R]观点2:开源模型效率不高,无法在商业领域与闭源模型竞争;
[三R]观点3:智能体是最重要的发展方向,但还不是业界共识。
[点赞R] 人工智能是这几年非常火热的行业,大模型作为人工智能的重中之重,很多人对大模型的理解存在误区。就像李彦宏所说,大模型之间的差距不是在缩小,而是会越来越大,而且需要不停地更新和改进,才能跟上用户的需求,同时也能提高效率。
[向右R] 大模型分为开源和闭源两类,在商业领域开源大模型效率是比不上闭源模型的。闭源模型可以通过大量用户分摊研发成本和硬件资源,从而实现更高的GPU使用效率。例如,百度文心大模型的GPU使用率可以达到90%以上,这种效率在开源模型中可能难以实现。
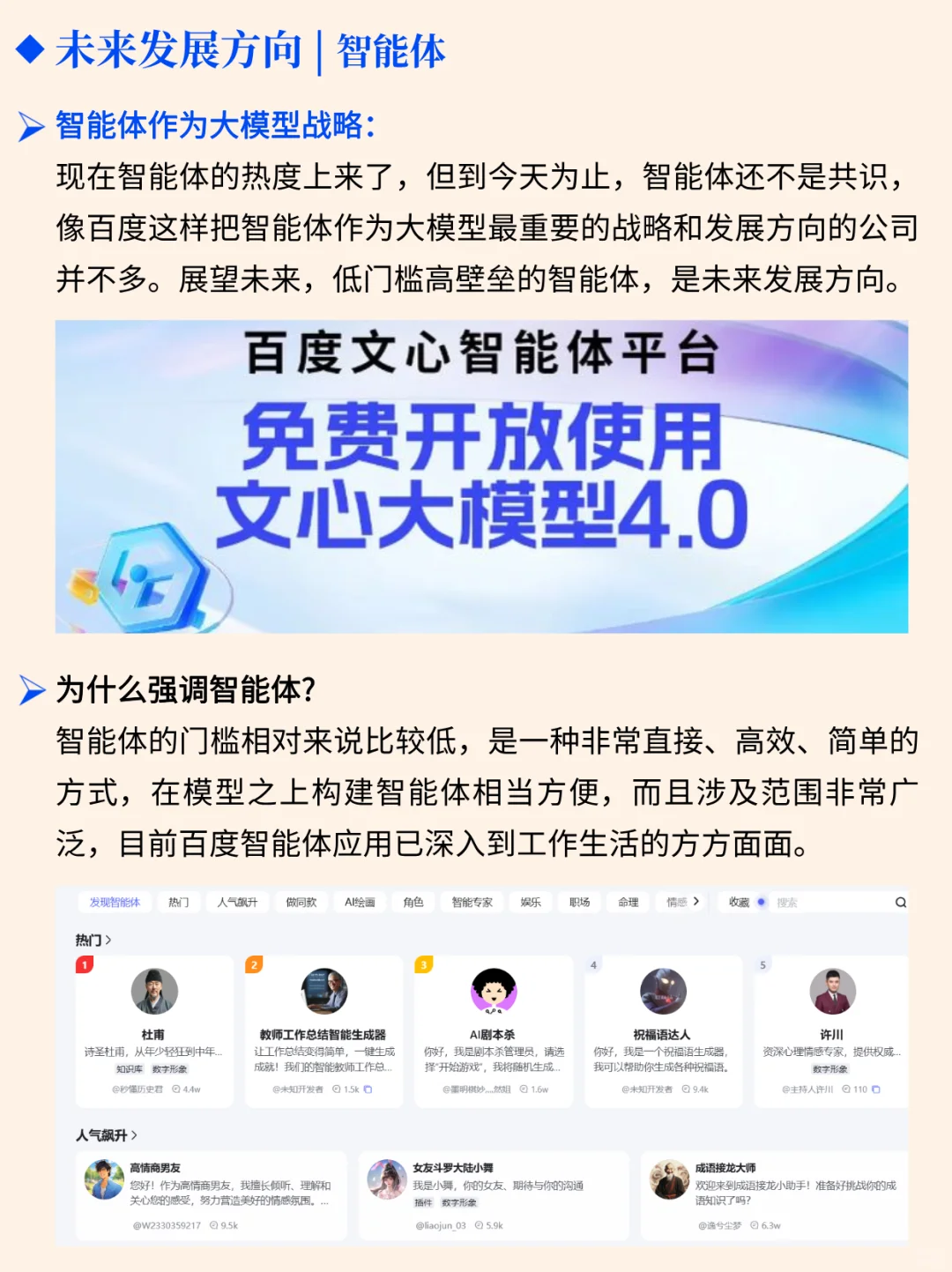
[向右R] 智能体作为大模型发展方向之一,能够自主执行任务、学习和适应环境的系统,但还没有在业界形成广泛的共识。而百度已经大规模押注智能体,如今基于文心大模型的百度智能体生态已经逐渐形成,像百度这样把智能体作为大模型战略和方向的公司可谓少之又少。
百度的文心大模型现在用的人越来越多,每天的调用次数超过6亿次,在实际应用中非常受欢迎。在AI这条路上,百度已经走的很远。