个人开发者训400亿参数大模型3090运行400亿参数大模型
打破科技巨头算力垄断,个人开发者联手也能训练超大规模AI模型?
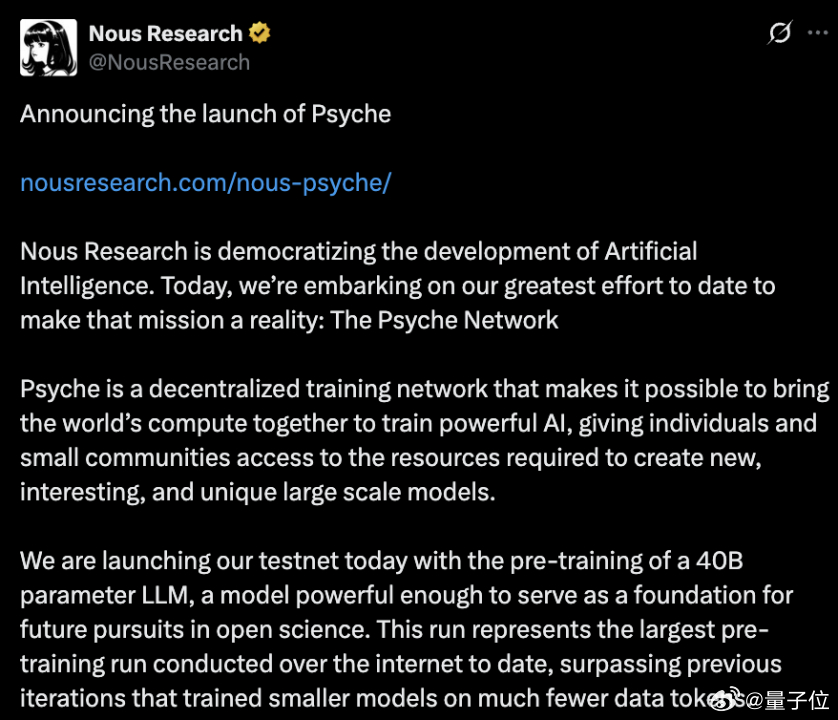
Nous Research宣布推出Psyche Network,可以将全球算力整合起来训练强大的人工智能。【图1】
Psyche是一个基于Deepseek的V3 MLA架构的去中心化训练网络,测试网首次启动时直接对40B参数LLM进行预训练,可以在单个H/DGX上训练,并在3090 GPU上运行。【图2】
以往类似规模的模型训练往往需要耗费大量的资源和时间,并且通常是由大型科技公司或专业研究机构凭借其雄厚的资金和算力优势来完成的。
Psyche的出现让个人和小团体也可获取资源创建独特大规模模型。【图3】
对此,有网友表示,Nous Research有潜力成为新的前沿AI实验室。【图4】
在传统AI训练中,数据需在中心服务器与分布式GPU之间高频传输,带宽不足会导致GPU利用率暴跌。
2024年Nous研发的DisTrO分布式训练优化器,通过梯度压缩(仅传输关键参数更新)和异步更新策略,将跨节点通信的数据量降低90%以上,突破了训练过程中的带宽限制,使得训练可以去中心化。【图5】
Psyche创建了一个自定义的点对点网络堆栈,用于协调全球分布式GPU运行DisTrO。
这个基于P2P(点对点)协议的专用网络层,无需依赖中心化服务器协调,全球GPU可直接通过加密通道交换梯度数据。
这一设计彻底摆脱了对传统云服务商高带宽网络的依赖,即使是家用宽带连接的GPU,也能稳定参与训练。
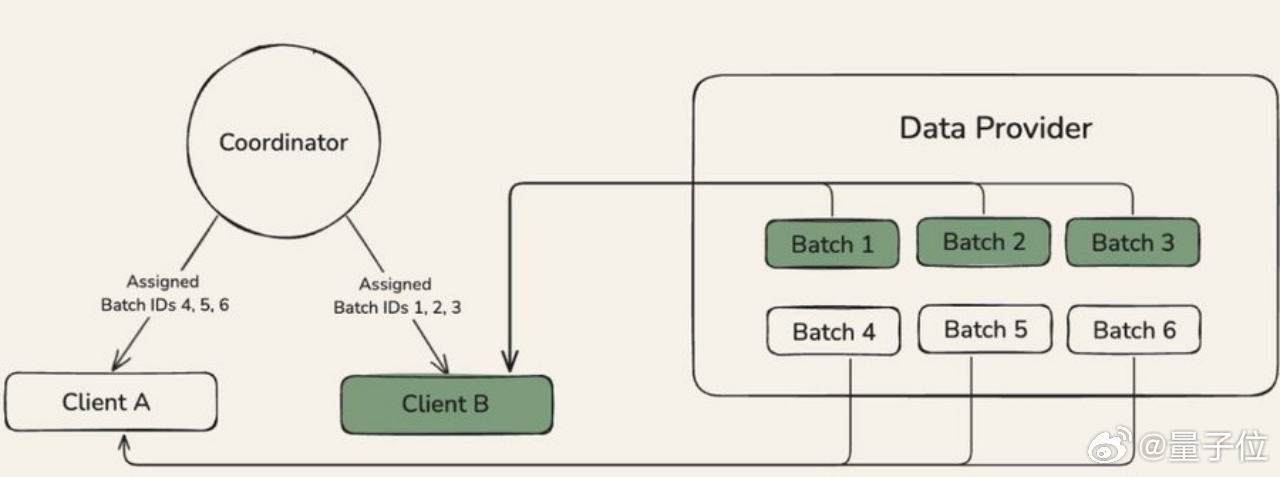
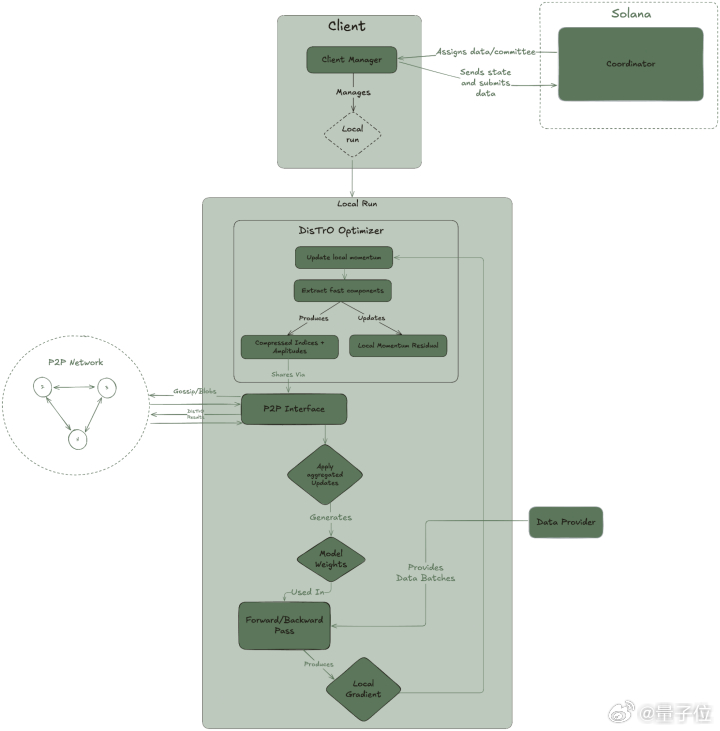
系统架构【图6】
Psyche网络架构有三个主要部分:
coordinator:协调器,存储有关训练运行状态和参与者列表的元数据。处理一轮训练中每个阶段之间的转换,且负责为运行中的所有客户端提供同步点。
clients:客户端,负责训练、见证和验证。每个客户端都保持自身状态与协调器同步。
data provider:负责提供训练所需的数据。可以是本地的也可以是HTTP或 CP提供者。
此前互联网公开的大规模预训练多由Meta、Google等巨头主导(如LLaMA 2的700亿参数模型),Psyche以去中心化模式实现同等级别训练。【图7】
Psyche首次测试网运行使用的是Deepseek的V3 MLA架构。
MLA通过低秩联合压缩键值和矩阵分解技术,降低计算复杂度与内存占用,使 400 亿参数大语言模型在有限算力下高效训练。
多头注意力机制与潜空间表示学习相结合,提升模型语言理解与生成能力;并且,旋转位置嵌入的运用,有效解决长序列位置依赖问题,从多维度保障了训练的高效性与模型性能的优质性。
数据集:使用了FineWeb(14T)、去除部分不常见语言的FineWeb-2(4T)和The Stack v2(1T),些数据集涵盖丰富信息,为模型训练提供了有力支持。
分布式训练策略:
- 模型并行与数据并行结合:将400亿参数拆解为128个分片,分布在不同节点进行 “模型并行” 训练,同时每个节点处理独立的数据批次(“数据并行”),通过DisTrO优化器同步梯度更新。
- 动态自适应批量大小:根据节点网络延迟自动调整每个批次的训练数据量(如高延迟节点使用较小批次,减少等待时间),使全局训练效率提升25%。
随着AI模型参数规模呈指数级增长,传统集中式训练模式正面临算力垄断、成本高昂和扩展性瓶颈的严峻挑战。
分布式训练的崛起,正在彻底改写这一格局。
就在几天前,Prime Intellect发布了首个分布式RL训练模型INTELLEC-2,引起了广泛关注。【图8】
Nous Research也称Psyche初始训练只是起点,后续计划整合监督微调、强化学习等完整的训练后阶段工作,以及推理和其他可并行工作负载。【图9】
谁能站稳分布式训练擂台?当然,我们期待更多更优秀的成果~
感兴趣的小伙伴可以到官方查看更加详细的内容。
博客:
训练仪表板:
代码:
文档:
论坛:
HuggingFace: